Sample-based Identification Eases Object Recognition Tasks

Markus Ulrich and Lutz Kreutzer
Many machine-vision systems use barcode data readers to identify products. Numerous companies manufacture hardware and software products to perform this task. However, using machine-vision systems to automatically identify objects without such imprints often requires more complex and expensive systems based on classification or template-matching algorithms.
When classification algorithms are used for identification tasks, the system integrator must first determine which specific features within an image can best describe the object. Multiple algorithms can be used to extract point, texture, or grayscale and frequency values within the image as identifying features. Although many machine-vision software products allow these features to be extracted, it is difficult to find the optimum features for a specific task.
The developer must decide which classifier is best suited for the chosen type of extracted features. Again, numerous classification methods are available that include neural networks, support vector machines (SVMs), Gaussian mixture models, or k-nearest-neighbor classifiers. Each of them has characteristic advantages and drawbacks that the developer must understand before choosing the optimum classifier.
Both the parameters of the feature extractors and the classifiers must also be optimized for the object recognition task. Since these parameters may not be intuitive, expert knowledge is required. This involves extensive evaluation of specific object types, which further increases the time it takes to develop object recognition systems. Major modifications to the set of objects to be identified may also require redesigning components of both feature extractor and classifier algorithms.
Although software products are available that attempt to hide the complexity of feature extraction and classification from the user, many parameters must be set by the developer to tune the application for robustness and speed. Furthermore, these products often do not scale well with the number of objects to be distinguished, and identification times become slow for large datasets.
If template-matching algorithms are used for object recognition, similar problems arise because identifying objects from a set of several hundreds or thousands by using matching is too slow for many applications. This is compounded in 3-D-based template matching where multiple templates are required for each object. Furthermore, only a few template-matching algorithms are robust to any deformations that may occur in the object; and objects with no fixed structure—such as salad, onions, or potatoes—cannot be characterized using template-matching techniques.
Sample-based identification
To overcome these limitations, MVTec Software has developed a novel sample-based identification (SBI) technique that can identify objects based on characteristic features such as color or texture, thereby eliminating the need for barcodes or datacodes as identifying marks. As part of the company's HALCON 11 software, SBI is capable of differentiating thousands of objects that may be warped or viewed from varying perspectives.
Like traditional object recognition software, SBI must first be trained. Offline, the developer provides an example image containing the object to be trained, specifying whether only gray-value texture information is used or whether color information should also be used.
For each image, SBI automatically extracts predefined features. Then attributes are internally computed for each extracted feature. Basically, the features and their attributes describe the texture and the color of the object. The full set of all attributes describes the object.
In the online phase, features and their attributes are computed from an object and the computed identifier queries objects in the system's database with the most similar attributes. The result is then returned as the identified object. The run-time of the identification is in the range of a few tenths to a few hundredths of a second even for very large databases that include thousands of different objects.
In practice, captured images might be acquired under different viewing angles, lighting conditions, sizes, and orientations than they were in the training phase. The objects under inspection may also be partially occluded or cluttered with other objects in the frame. However, SBI is robust to such conditions. In Fig. 1, a single image is used to train the SBI using gray-value and color information and allows the SBI to distinguish the posters from one another.

One major advantage of SBI is that only a single parameter needs to be set by the developer. This determines whether only texture or texture and color information should be used for identification. The choice of this parameter strongly depends on the application; in applications where the color temperature of the light source or the color of the objects may vary, color information should not be used. Other available software products may require the specification of more (and sometimes nonintuitive) parameters.
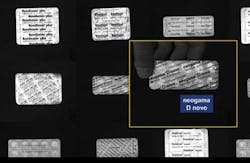
Sample-based identification approaches may also be used where complex optical character recognition (OCR) tasks must be performed. In blister-pack inspection, for example, identifying the blister packs by using OCR may be difficult because different blisters use different fonts in a variety of sizes, and font segmentation is hampered by surface reflections (see Fig. 2). In such applications, SBI methods may prove more effective.
Identifying 3-D objects
In other applications, objects may not be planar but have a 3-D shape. To identify 3-D objects from an arbitrary viewing direction, for example, within an automatic supermarket self-checkout, multiple example images of an object under different viewing conditions must be used for training. In such cases, it is often necessary to present images rotated by 45°. This is only necessary for object rotations out of the image plane since the SBI is rotationally invariant within the image plane. Several evaluations have shown that this approach can be used to identify 3-D objects robustly.
More demanding applications require the identification of deformable (planar or 3-D) objects. Here, the appearance of objects such as bags of potato chips, newspapers, fruits, vegetables, or salad in the image may change depending on the objects' deformation (see Fig. 3). In these situations, the identification process can be further improved by using depth sensors such as time-of-flight (ToF) cameras or structured-light sensors. If the object always lies on a flat table with constant distance to the camera, depth image data can be segmented by a threshold operation and used to increase the robustness of the system.

In many machine-vision applications, the set of objects that must be identified may change during daily use. For instance, in automated supermarket checkout systems, the assortment of goods required to be classified may change daily. To do so requires sample images to be deleted and added as necessary. After having removed old samples and adding example images of new products, the training process is restarted. This retraining step is very fast and only takes a few milliseconds. After training, the identifier can then be applied to run-time images.
Markus Ulrich, PhD, and Lutz Kreutzer, PhD, are with MVTec Software (www.mvtec.com).
Vision Systems Articles Archives