What’s the difference between machine learning and deep learning?
Supervised learning methods offer inherent advantages over convolutional neural networks
Dr. Jon Vickers
Deep learning has been a topic of great interest and much discussion recently in the world of machine vision.
It is especially well-suited for machine vision applications that have challenging classification requirements. Deep learning is not a technical term, but generally involves the use of neural networks. The availability of convolutional neural networks (CNNs) as a tool within commercially-available image processing packages has made this technology available to a much wider audience.
Nevertheless, practical applications still require significant input from vision specialists, especially in the training phase. A neural network is a software or hardware model of the brain, where simple decision-making or logic units (neurons, perceptrons) are combined in their inputs, outputs and decisions to make a large, complex decision-making system (network) that can imitate the capabilities of the brain.
At the simple level, an untrained neural network ‘knows’ nothing and gives random or chaotic results until the neurons and the network have been ‘trained’ to give the desired output.The system is self-learning, but is critically dependent on the size and quality of the training data set and the architecture of the neural network. Other machine learning methods, as part of a supervised learning approach, can be a powerful alternative.
Unsupervised learning
Neural networks are ideally suited to unsupervised learning applications where there is no prior knowledge and all knowledge is inferred from the training set.
In general, the data set and possibilities are so large that statistically there will be a solution. The tools are trying to find classifications within the data and it may require a huge amount of learning to get there and a lot of ‘blind alleys’ encountered before a solution emerges.
This is similar to a human dealing with a real-world image. The human learns to identify parts of an image based on ‘experience’ – exposure to a large number of similar sets of data and feedback about whether the decision was correct. The same follows for artificial neural networks. Since large training sets are required (typically around 1000 training images per class), a graphics processing unit (GPU) would normally be required to make the training fast enough to be acceptable, although once trained, neural networks can often be used to evaluate unknown images using a CPU.
An alternative approach is to provide pre-trained networks which can then be used to develop an application with fewer training samples. Still, the network is pre-trained on a large and diverse dataset that contains many thousands of training images that are required to learn general features.
Supervised learning
Deep learning is a subset of the category of machine learning. Machine learning contains a class of algorithms capable of supervised learning applications. Supervised learning means that there is some prior knowledge in the training set and the challenge is to create the function to connect the inputs to the desired outputs, and this requires a level of human input.
The choice and combination of features affect the ease with which supervised learning can be accomplished. Consequently, choosing the most suitable features is critical. Labeled input images are used to specify the features so that the algorithm can generate a function to produce the desired output.
There are a number of supervised machine learning methods available, including support vector machines, ridge regression, decision trees, K-nearest neighbors and Gaussian mixture models. Since these supervised learning approaches involve a level of direction as to shaping the algorithm to deliver the desired outcome, far fewer training images are required compared to neural networks.
Supervised learning methods also generally have much lower computational requirements during training compared to a CNN. They are generally faster to train and require only a CPU rather than a GPU. A staged learning approach is often adopted. The first stage provides an indication of the level of success of the outcome before a full ‘learn‘ takes place.
Supervised learning tools
The supervised learning methods mentioned previously in this article all have different algorithmic approaches to establishing classifiers for machine vision applications. Many image-processing libraries will contain tools based on these methods. Three examples are the CVB Minos, CVB Manto and CVB Polimago tools found in the Common Vision Blox hardware-independent machine vision toolkit from Stemmer Imaging (Tongham, UK; www.stemmer-imaging.co.uk).
Tools such as these can address many of the applications handled by CNNs, as well as some such as pattern recognition—an extremely important task in machine vision—which are typically not well handled by CNNs.
Decision tree
CVB Minos is a decision-tree based pattern recognition tool which uses real grayscale features. For object recognition CVB Minos uses discrete features in the gray value range that are automatically extracted from sample images during the training phase. It not only detects features to differentiate between each trained object type, but also uses negative examples in the sample images to further secure correct detection and classification. This provides the ability to differentiate between two similar objects and also to deal with patterns that are mixed with varying backgrounds, for example in OCR or security print used in bank notes or credit cards.
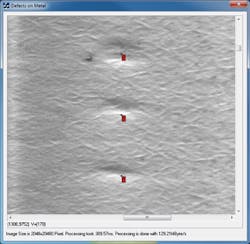
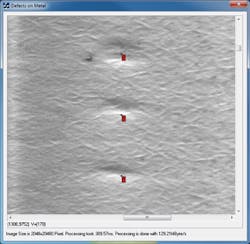
Figure 1: CVB Manto is used to identify defects in a metal surface.
Support Vector Machine
CVB Manto uses support vector machine methods to separate the object classes using features in an image such as correlation, geometrical connections, texture and color. It can be used for the identification of objects with organic fluctuations in their composition, such as different types of fruit, gender classification in human faces and the identification of defects in surface textures.
Manto learns to identify the patterns of interest from a set of training images and then calculates a confidence factor for its classification choice for each test image. It typically requires 50-100 training images per class, using a CPU for training. Figure 1 shows the use of Manto to identify defects in a metal surface.
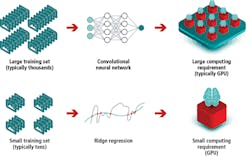
Figure 2: Polimago requires comparatively fewer training images than typical pattern matching applications (typically 20 – 50 images per class), especially compared to CNNs.
Ridge regression
CVB Polimago uses the ridge regression supervised-learning method. This was designed for applications including pattern recognition, pose estimation and object tracking. For pattern matching in general, any geometrical transformations such as rotation, size changes and tilting, as well as changes in illumination need to be learned during the teaching phase in order to deliver an accurate classification rate.
The challenge then is to be able to generate a suitable set of training images to cover all of the possible variations. CVB Polimago, however, requires comparatively fewer training images, typically in the range of 20 – 50 images per class, especially compared to CNNs (Figure 2).

Figure 3: CVB Polimago identifies objects on a tray and displays their orientation and scale.
The algorithm itself generates synthetic views of the model from the initial training set to simulate various positions of the object in real life. In this way, the algorithm is able to learn the variability of the corresponding pattern by automatically generating thousands of training images and can provide recognition rates at high speed.
One of the inherent advantages of the ridge regression method is that it cannot be over-trained. At worst, the algorithm would saturate and fail to further improve, but that would only be expected after thousands of training images, which are not generally required.

Figure 4: CVB Polimago’s ridge regression algorithm is used in two different applications—vehicle classification and OCR reading on a silicon wafer.
CNNs, by comparison, can be over-trained and counter-measures are necessary to avoid this. The extremely-high recognition rates achieved are an important base for pick-and-place applications such as robot gripping and the tracking and tracing of objects. Figure 3 shows Polimago identifying objects on a tray and displaying their orientation and scale.
Comparing results
CNNs and supervised learning tools lend themselves to similar sorts of applications:
- Difficult defect detection – scratches, dents, marks which are unknown inadvance.
- Difficult OCR – such as handwriting, deformed text, stamped characters that varysignificantly.
- Outdoor applications - where ambient illumination changes theappearance.
- Organic applications – faces, food, plants where the real appearancevaries.
There is no definitive rule as to which technique will work best for any given application. Figure 4 shows images, comparing the performance of CVB Polimago’s ridge regression algorithm against a CNN in two different applications: vehicle classification and optical character recognition on a silicon wafer.
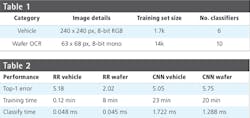
Table 1 gives details of the training image sets and the number of classifiers used in the comparison, while Table 2 gives the results for training time and classification time. This serves to highlight the variations that are possible between different tools. The quality of the classification results after training must also be assessed in order to determine how successful the process has been and whether further training steps may be required or even the use of a different tool. The type of algorithm alone is not a solution. The implementation of the algorithm is critical.
Dr. Jon Vickers, Technical Manager and Product Manager, Stemmer Imaging (Tongham, UK; www.stemmer-imaging.co.uk)