Fundamentals of deep neural networks
You’ve probably already heard of deep learning, or at the very least have experienced the effects of deep learning in your daily life. Deep learning is often used in applications such as object identification, facial or voice recognition, or detecting traffic lanes and road signs in autonomous driving applications.
At the core of this technology is deep neural networks. Although the process of designing and training a neural network can be tedious at first, the results can be impressive—meaning that the deep learning algorithm can better identify things like a spoken word in a voice recognition device or a potentially cancerous cell in a tissue sample than traditional techniques.
Three technology enablers are helping engineers and scientists make deep learning to this degree of accuracy possible:
- The widespread availability of massive labeled datasets. The more data, the greater potential for a highly accurate model. Labeled datasets of all kinds, created by researchers and companies, are freely available and useful for training algorithms across many types of objects. Labeling tools are also making the process of creating custom datasets easier.
- Advances in computing power. High-performance super computers with multiple graphics processing units (GPUs) significantly reduce the time it takes to train the massive amounts of data needed for deep learning—in some cases from weeks to hours.
- Pretrained models. GoogLeNet, AlexNet, and other pretrained models offer users ready-built starting points to perform image recognition using a process called transfer learning. Here, models are repurposed to build a second model to perform a new task. This approach enables scientists and engineers to take advantage of the latest research and apply it to their specific problem using their own datasets.
What makes deep neural networks tick?
When developing deep learning algorithms for video and images, many scientists and engineers incorporate convolutional neural networks (CNNs) for many types of data including images, and other network architectures such as LSTMs which are popular for signal and time series data.
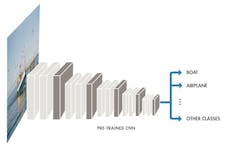
A CNN takes an image, passes it through the network layers, and outputs a final class. The network can have tens or hundreds of layers, with each layer learning to detect different features of an image. Filters are applied to each training image at different resolutions, and the output of each convolved image is used as the input to the next layer. The filters can start as very simple features, such as brightness and edges, and increase in complexity to features that uniquely define the object as the layers progress.
Each layer in the network absorbs data from the previous layer, transforms it, and builds on it. The network continues to refine the details of what it learns from layer to layer. It’s important to note that the network learns directly from the data with no outside intervention required.
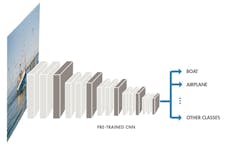
Engineers and scientists have many types of layers available when designing a CNN. The layers commonly found in most models are:
- Convolution: Applies a set of filters to each input image, with each filter activating specific features from the images.
- Rectified linear unit (ReLU): Enables faster and more effective training by mapping negative values to zero and maintaining positive values.
- Pooling: Performs nonlinear downsampling to simplify the output, which reduces the number of parameters the network must learn.
Get started with deep learning
At a high level, the deep learning workflow looks like this:
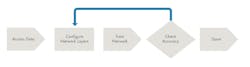
For engineers just getting started, here are some few tips for each step of the way:
1. Access data: Here, we want to access the training dataset. In this example, we quickly import MNIST, which contains 60,000 samples of digits 0–9.
Tip: Make sure you have enough data. Typically, a neural network’s accuracy will improve with more images.
2. Configure network layers: As mentioned above, a common neural network architecture consists of convolution, activation, and pooling layers. Here, we combine these layers to produce our neural network layers.
Tip: There is no specific formula for selecting layers, which is why it’s often best to start with a small number of layers and see how well they work or use a pretrained network to determine the best approach.
3. Train network: Training a deep learning model can take hours, days, or weeks, depending on the size of the data and the amount of processing power you have available. Because this example contains very simple images, the network can train in a matter of minutes.
Tip: Use a powerful GPU or cloud resources to speed up processing time.
4. Check network accuracy: The architecture above gets 90% accuracy on the MNIST dataset, which is a good start, but 99% is possible. To achieve this, we add more layers, including batch normalization layers, which will help speed up the network convergence (the point at which it responds correctly to new input).
Tip: Deep learning requires multiple iterations. Plan on spending time changing the network configuration, training parameters, and training data until the final accuracy is acceptable.
Several software tools exist to ease engineers and data scientists into the implementation and training of deep learning algorithms. One example is Deep Learning Toolbox from MathWorks, which adds new deep learning capabilities that simplify how engineers, researchers, and other domain experts design, train, and deploy models. The toolbox also works with other deep learning frameworks through importing and exporting model capabilities (see a list of latest pretrained models).
Learn more about the topics in this blog:
- What Is a Neural Network?: Learn the three things you need to know about neural networks.
- Deep Learning Toolbox: Find out how you can create, analyze, and train deep learning networks with Deep Learning Toolbox.
- Create Simple Deep Learning Network for Classification: This example shows how to create and train a simple convolutional neural network for deep learning classification.
- Deep Learning Toolbox Examples: Check out this complete list of examples to get started with deep learning.
- Introducing Deep Learning with MATLAB: Read the ebook to learn the basic techniques of deep learning, including machine learning vs. deep learning and CNNs, and get access to examples, tutorials, and software to try deep learning yourself.