4D tracking system recognizes the actions of dozens of people simultaneously in real time
Microsoft (Redmond, WA, USA; www.microsoft.com) has developed a 4D tracking system based on simultaneous use of multiple 3D Time of Flight (ToF) cameras, volume measurement, and denotations of time. The system can recognize the behavior of and track dozens of people simultaneously, with the potential to deal with much larger numbers.
The engineering and construction industries often make use of 4D modeling. A 4D model of a proposed building, designed around a construction schedule, can show a viewer what the building should look like at specific points on the project’s timetable. If the building design changes, and those changes affect the project timetable, the 4D model of the proposed building alters accordingly.
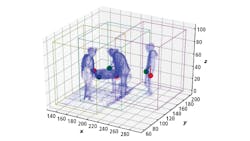
In traditional 3D imaging like LiDAR, point clouds represent the outlines of objects. These 3D imaging systems do not measure the space inside of those outlines. Microsoft’s new system, on the other hand, uses multiple Azure Kinect ToF cameras to image and voxelize space, or convert the space into 3D voxels instead of 2D pixels.
“We want to have some kind of solid model,” says Dr. Hao Jiang, one of the 4D tracking system’s inventors, a researcher at Microsoft. “We want to know whether a voxel, a point in space, is occupied by something or not occupied. That’s the occupancy map.”
The tracking system captures voxel data at 30 fps. Each voxel in each frame has X, Y, Z coordinates and a fourth identifier, T—the system’s titular fourth dimension, time—which marks the instance in which the voxel data was captured. The occupied voxels translate into volumetric data, or the amount of occupied space in the frame, at which point the 4D tracking system can build a 3D map of the space (Figure 1).
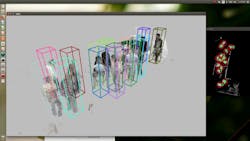
The tracking system’s algorithms then break the total volume of the occupancy map into partial volumes, or masses of occupied voxels. A detector algorithm running on a convolutional neural network scans the partial volumes for patterns that may represent a person (Figure 2). Pre-pruning empty voxels before the algorithm sweeps through the scene to look for potential people optimizes the procedure.
Detector algorithms (or classifiers) in imaging generally weigh probabilities as to whether a group of pixels represent what the algorithm thinks they represent, like a face or a street sign, based on training data. Microsoft’s 4D tracking system weighs the probabilities that the voxels of a partial volume represent a person by tracking the partial volume’s movement through time.
“Normally a person doesn’t move from one point and jump ten meters away,” said Jiang. “If we look at some points in surrounding, nearby regions of the occupancy map, we can follow the partial volume and determine if it’s actually a person or not. The classifier alone could have 98% accuracy, but with this tracking procedure we can get the system up to almost 100% accuracy.”
Action recognition through time travel
Once the 4D tracking system has successfully identified and tracked volumes that represent people (Figure 2) the system can then observe the person’s movement and the change in the volume data through time and recognize the action a person takes.
“The system uses several clues,” says Jiang. “One thing is the shape. If you look at the point cloud generated by the volume data, you’d know that a person is sitting because the leg is bent. The shape is quite different from the standing pose.”
“Also, we use temporal information,” Jiang continues. “When somebody sits down, there’s a motion structure. The volume evolves from the standing shape to the sitting shape. This also gives us a clue that the person is sitting down.”
The tracking system learns to recognize individual actions from recordings of sessions in which a single person performs a specific action, such as sitting down. The captured volume data of the person sitting is labeled sitting. Each time instance within that clip in which the person is fully seated, versus instances in which the person is in motion, i.e. standing up or sitting down, is also labeled sitting.
Clips of this procedure, generated by multiple people, train a classifier algorithm on how to recognize the action of sitting. The classifier algorithms used by the 4D tracking system were created from the ground up by Microsoft.
“Not a lot of people are working on this kind of volume data for action recognition,” says Jiang. “We don’t capture data and later recognize actions. The system can run the tracker and action recognition in real time. We can see the result right away, on the screen. That’s something quite different from the traditional way.”
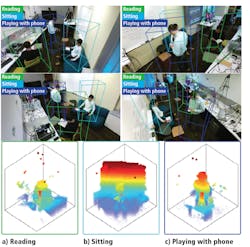
Paying close attention
In early testing, the 4D tracking system was trained to recognize sixteen actions including reading a book, sitting, pointing, opening a drawer, eating, yawning, and kicking (Figure 3). Some of these actions look very distinct from one another. Others, like drinking or holding a phone, can look quite similar through the low-resolution occupancy map.
Microsoft developed an auxiliary attention module that incorporates Recurrent Neural Networks (RNN) to differentiate between similar actions. The auxiliary attention module functions like an automated Region of Interest (ROI) generator.
“If somebody’s drinking something, we want to look at the head region,” says Jiang. “We don’t want to look at the entire volume. Leg movement has nothing to do with drinking and probably has little correlation.”
He adds, “The attention system generates probability weights as to whether specific volume data applies to a recognizable action. The system then adds weight to the coefficients in some regions of the volume and remembers the results, generating a new feature to assist in action recognition.”
Unlike the action recognition algorithm, the auxiliary attention module doesn’t require instruction on where to look. The module trains itself by learning, through repeated action recognitions, which specific parts of the volume data are most relevant for recognizing specific actions. If it appears as if someone is reading a book, the module pays more attention to the hand and arm regions of the volume data to help make the determination as to whether they are reading. If it seems like someone may be engaged in the action of kicking, the auxiliary attention module begins paying more attention to the leg and foot regions.
“The neural network looks at all these examples and determines where weights should be placed to achieve better results,” says Jiang. “The weights are dynamic, not predefined. The module sees that someone is probably completing a specific action and assigns weights to the relevant regions to confirm what action is being taken.”
Microsoft tested the accuracy of its system against five other systems previously used for action recognition: ShapeContext, Moment, Skeleton, Color plus Depth, and PointNet. Each system was fed the same training data and fine-tuned for performance. Tests were conducted in a cluttered scene of multiple people of varied body shape, gender, and height, and objects like tables, chairs, boxes, drawers, cups, and books.
The people in the tests, placed into five test groups, performed the sixteen actions that the 4D tracking system has been trained to recognize. Each person in each frame was assigned an action to perform. Successful action classification was defined as a system predicting an action label that matched the assigned action. Four RGBD cameras captured video of the test environments. ShapeContext achieved an average action recognition accuracy of 40.38%; Moments achieved 44.9%; Skeleton achieved 54.94%; Color + Depth achieved 59.96%; and PointNet achieved 57.78%. Microsoft’s system, on the other hand, achieved an average action recognition accuracy of 88.98%.
Scaling up
In the largest test of the system to date, the researchers emptied a floor of the Microsoft office in Bellevue, WA, USA, amounting to several thousand square feet, set up 26 Azure Kinect cameras, moved in some furniture to simulate an office environment, and brought 50 people into the room as test subjects.
Power and bandwidth constraints, not the number of people being tracked, limit the potential size of the tracking system. Accuracy of action recognition, according to Jiang, has no correlation to the number of people as the system tracks each person individually and uses individual volumes for action recognition.
“The density of people does have some effect on accuracy,” says Jiang, “but handling clutter and crowds is in fact the strength of the proposed approach. The number of people does affect the time complexity of the method. If the system frame rate drops, we can just add more GPUs because the method allows the computation to be distributed into multiple cards or machines.”
Microsoft’s 4D tracking system does not currently recognize objects. The low resolution of the point clouds represents the most significant challenge. Contextual observation may provide a solution.
“We do recognize some objects in context, for instance during shopping activities,” says Jiang. “The customers pick out some products from the shelf, and we built a classifier to recognize that product, the box. We have a pretty accurate hand localizer. If we know where the hand point is, we can recognize the object in the hand.”
For another example, the action of reading depends on the presence of a book in the hands of the subject. If the system can successfully recognize the action of reading, it might also learn to recognize the partial volume of a book, as the volume data of a person recognized as reading likely includes volume data for the book being held by that person. This technique may work for larger objects. Recognition of smaller objects—such as a tube of lipstick—may require the addition of RGB image data.
“We can use the point cloud to localize the hand quite easily, and then we can project the color image,” said Jiang. “That is probably the right way to do detailed object recognition with our new system.”
This story was originally printed in the November/December 2019 issue of Vision Systems Design magazine.
About the Author

Dennis Scimeca
Dennis Scimeca is a veteran technology journalist with expertise in interactive entertainment and virtual reality. At Vision Systems Design, Dennis covered machine vision and image processing with an eye toward leading-edge technologies and practical applications for making a better world. Currently, he is the senior editor for technology at IndustryWeek, a partner publication to Vision Systems Design.