Go GUI to train neural networks on 2D objects

While traditional image-processing software relies on task-specific algorithms, deep learning software uses a network to implement user-trained algorithms to recognize good and bad images or regions. Traditionally, creating a model that classified objects with a high degree of accuracy required hundreds or even thousands of manually classified images to train the system. Gathering and annotating such complex datasets has proven to be an obstacle to development, hindering deep learning adoption in mainstream vision systems.
Fortunately, the advent of specialized algorithms and graphical user interface (GUI) tools for training neural networks is making deep learning easier, quicker, and more affordable for manufacturers. What can manufacturers expect from these deep-learning GUI tools, and what’s the benefit of employing them?
Deep learning vs. traditional methods
Deep learning is well-suited to environments in which variables such as lighting, noise, shape, color, and texture are common. A practical example that shows the strength of deep learning is scratch inspection on textured surfaces like brushed metal (Figure 1). Some scratches are visible even to the naked eye. Other scratches can be much more subtle, with a contrast close to the textured background. Traditional rules-based techniques often fail to detect such subtle defects without substantial programming, whereas deep learning-based inspection tools can be trained much more easily using images.

In the early days of deep learning systems, programmers would first create a raw neural network structure and then train the network. A trained network is called a model, and today open-source, pretrained models are available. Because the model is pretrained with generic images, the user just needs to show the model a limited number of images specific to the application. This requires a training/testing set of images called the dataset.
Building the dataset involves capturing and annotating (labeling) still images to tell the neural network what the image represents. For example, if the inspection application only needs to detect a small number of very obvious anomalies, a sample of images annotated as “good”—representing products that will pass inspection—may be all that’s required as the first steps of neural network training.
An inspection application designed to detect a large number of subtle defects may require a larger set of images that demonstrate all the various defects, which would indicate a “bad” result or a product that wouldn’t pass inspection. In most cases, when the deep learning inspection system must consider a large number of variables, it will require an equally large training dataset.
Typically, around 80% of this total dataset is used to train the neural network model. The remaining 20% of the images are used to test the trained model. Any incorrect results may be manually corrected, i.e., an image that the model identifies as “good” that is actually “bad” may be manually annotated as “bad.” This image is then fed back into the model for another training cycle, called an epoch.
GUI-based deep learning tools simplify the process of creating these training and testing images by making it easier to annotate the images, even for quality control staff and other technicians who don’t have programming and artificial intelligence (AI) background (Figure 2). Such users can employ graphical annotations, predefined hyperparameter values, and visual model assessment, among other features, to create datasets and models.
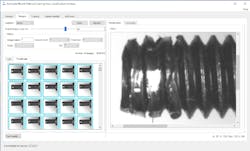
These tools facilitate the creation of both simple and complex datasets. Object detection or segmentation applications, for example, are trained to detect objects within images or break an image down into its component parts. An object detection application may be trained to detect apples in images of mixed fruit types. A segmentation application may be trained to determine which part of an image of a busy highway represents only the road versus the sky or the grass in between lanes.
In the sample training image in Figure 3, the user has created boxes around different types of objects such as nuts, screws, nails, and washers, which the detection model must locate. It’s not a simple task because the image is crowded, and some of the objects are reflective and partly occluded. While using rules-based algorithms to achieve the high robustness required to accurately detect specific objects within images such as these would be time-consuming, a deep-learning GUI tool makes it possible to manually annotate complex training images. The good news is that an object-detection algorithm may be trainable with just a few tens of training images, saving considerable time.

By facilitating quicker turnaround for both simple and complex images needed for model training and fine-tuning, a GUI-based deep learning tool reduces the amount of time required to configure inspection software. This proves especially important over the lifespan of the model because result accuracy usually degrades over time, owing to changes in environmental conditions or other variables.
Testing results made clear
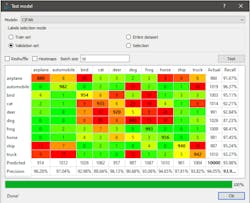
A confusion matrix measures how often a deep learning model successfully identifies different objects. In the sample confusion matrix in Figure 4, the column on the right labeled “Actual” indicates how many total images in the dataset depict the object identified on the left. The dataset includes 960 images of an airplane and 987 images of a ship, for example.
GUI-based deep learning tools can represent confusion matrix results in simple charts, making it easy to identify where the model performs well and where it’s failing. In this example, the model confused an image of a dog for an image of a cat in 86 out of 1026 examples. The model may require further training to correct for these errors.
Heatmaps are another critically important diagnostic tool. When used in anomaly detection, for example, a heatmap highlights the location of defects. When the user sees the heatmap, they assess whether the model classified the image good or bad for the correct reasons. If the ground truth image depicts a good product but the model classified the image as a bad product, the user can look at the heatmap for more detailed information and determine how best to correct the error through another epoch. Figure 5 demonstrates using heatmaps in a screw-inspection application.

During training, the user can monitor two key metrics: loss functions and accuracy. The loss functions show the difference between current model prediction (output of neural network) and expectation (the ground truth, or what the user knows the object represents). These loss functions should approach zero while training. If they diverge, the user may have to cancel the training session and alter the training data or the model’s hyperparameters.
If the training model properly classifies samples, the accuracy should approach 100% during training. In practice, though, most applications achieve between 95% and 100% accuracy. After training is complete with acceptable accuracy, the model is ready to use in production.
Deep learning for the masses
The migration toward GUI-based deep learning tools such as Teledyne DALSA’s Sherlock software is democratizing deep learning in vision systems. With software that frees users from the rigorous requirements of AI learning and programming experience, manufacturers use deep learning to analyze images better than any traditional rules-based algorithm.
And with the development of deep learning models thus made easier, the potential applications for deep learning have also gone far beyond traditional machine vision environments such as production facilities and warehouses. Deep learning systems are currently found in many embedded applications, such as smart cameras that monitor traffic patterns and smart shopping systems that allow consumers to pay for goods as they place them in a shopping basket. The easier the training tools, the more freedom vision system designers have to find new ways to employ these powerful deep learning models.
Bruno Ménard is software director at Teledyne DALSA.