Towards compressive sensing
Compressive sensing (CS) is revolutionizing the study of signal and image processing by promising to minimize the amount of data collected by a given sensor without sacrificing the information content of the signals they observe. Because most images are highly compressible, this new sensing paradigm is opening doors for significant advancements.
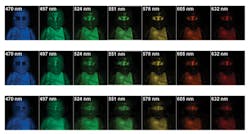
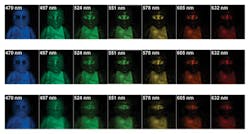
Approaches to CS cameras include coded-aperture spectral snap-shot cameras like that first introduced at Duke University by David Brady (http://bit.ly/2c15VRD) who developed a CS technique for extracting color using a monochrome camera. These cameras offer such features as multispectral color spanning the visible and NIR ranges as depicted in Figure 1 (http://bit.ly/2cpq0QW).
Other approaches to CS cameras include ultra-thin lens cameras where a thin-layer optic is fused directly to the surface of the image sensor to create cameras thinner than a dime. Rice University's FlatCam (Figure 2) shares its heritage with lens-less pinhole cameras, but instead of a single hole, it features a grid-like coded mask very close to the sensor.

FlatCam employs a Sony ICX285 CCD color sensor covered by a layer of quartz and a second thin-layer of chrome. The chrome layer acts as an opaque mask with pin-holes distributed randomly across the sensor. These holes behave like an array of pin-hole cameras with each pin-hole capturing a slightly different set of light. Like much larger light-field cameras, the picture can be focused to different depths thanks to CS algorithms after the data is collected.
CS shifts power consumption from the sensor to the processor, which is becoming ever-less power hungry. Collecting only the data required on the sensor side saves more power than the processor uses to reconstruct the image for a net savings in power and memory usage, allowing more images to be taken and stored on the device. Consider that the processor powering your smartphone may achieve 115 gigaflops while consuming 3-4W power while the LED flash in the camera consumes 0.5W (http://bit.ly/2cgRJ9a).
Moving forward, these sensors will find a home with depth sensing to produce vision systems that not only capture the size and shape of visible objects but can also identify material properties. By augmenting smart cameras for medical purposes or improving facial recognition, CS-enabled hyperspectral imaging could revolutionize telemedicine or smart spaces/home personal assistants. Vision in automobile navigation, for instance, would benefit from better night vision and material identification.
Daniel Lau
Professor of Electrical and Computer Engineering
University of Kentucky
