Image Capture: Panoramic camera employs dynamic vision sensors for 3D imaging

Applications such as bin picking require the use of stereo vision systems to determine the three-dimensional (3D) location and orientation of parts. In such applications, images from stereo cameras are used to generate a disparity map from which depth information can be calculated. While useful, such systems provide only a limited field of view and cannot be used in robotics and surveillance applications that require 360° panoramic 3D images to be generated.

While LIDAR-based systems such as the HDL-64E from Velodyne (Morgan Hill, CA; http://velodynelidar.com) can be used for obstacle detection and navigation of autonomous ground vehicles, their used of multiple laser emitters makes them expensive. To reduce the cost of such panoramic imaging systems, Dr. Ahmed Belbachir and his colleagues at the Austrian Institute of Technology (AIT; Vienna, Austria; www.ait.ac.at) have developed a 3D panoramic imaging camera based on dynamic vision sensors.
Jointly developed with Thales (Paris, France; www.thalesgroup.com) the TUCO-3D camera system employs two 1024 x 1 image sensors integrated onto a stereo sensor board. In turn, this sensor head is mounted onto a scanning platform that contains a motor and slip ring from Jinpat Electronics (ShenZhen, China; www.slipring.cn) that allows data from the two imagers to be routed to a camera head module. This FPGA-based camera head module is used to configure the camera head module and transfer data to a gigabit Ethernet interface.
Unlike traditional linear CCD or CMOS-based line scan imagers where photons impinging on each pixel are converted to electrons at a synchronous data rate, the two line-scan imagers used in the TUCO-3D camera are based on the principle of asynchronous imaging. These dynamic vision sensors consist of autonomous pixels that independently and asynchronously generate an output based on temporal contrast changes in the scene.
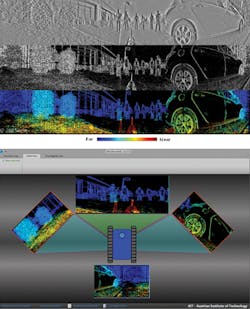
Since an output event from pixels will only be generated if the contrast in a scene changes, data transmission rates from the imagers are lower than those of synchronous devices. This is especially important since the camera head containing the devices rotates at 10 revolutions per second, generating 2 x 2500 x 1024 edge maps. After image data is transferred to a PC over the Gigabit Ethernet interfaces, a correspondence between the outputs of the two imagers must be computed.
"Classical stereo vision makes use of finding correspondences between two images of the same scene taken from two different viewpoints," says Belbachir. "However, the two dynamic vision sensors do not generate synchronized pixel data that correspond to the intensity of light falling on each pixel but temporal events that can be considered as sparse features."
Using classical techniques, pixels where no such temporal events occur would then be considered as matching pixels, which would obviously be an incorrect assumption. Instead, Belbachir's event-driven reconstruction algorithm is based on gradient profiling to find feature correspondences and calculate depth information.
After stereo matching, a color coded depth map of the panoramic image can be generated with a depth accuracy ranging from 3-20% for distances between 1-10 m. While at present the image reconstruction is PC-based and can be performed at 1 fps, a real-time implementation is possible using the FPGA within the TUCO-3D's camera head module.