IMAGE PROCESSING: Processor targets embedded imaging applications
Bridging the price/performance gap between reprogrammable FPGAs and custom ASICs has long been the goal of many semiconductor vendors. To do so, multiprocessing systems that incorporate a number of highly connected programmable processors have been used to increase the speeds of compute-intensive image-processing tasks. Originating in silicon architectures dating back to the Inmos Transputer in the 1980s, these concepts used specialized programming languages such as Occam to support channel-based inter-process and inter-processor communication.
While the original Transputer only featured single processing cores and required multiprocessor systems to be configured from a number of devices, the advent of very large-scale ICs has allowed silicon designers to place multiple processor cores on a single die. Better still, because these multiprocessors are now offered with more familiar languages such as C, programming is more efficient.
Emulating the concepts pioneered by Inmos, for example, companies such as Ambric introduced multiple instruction, multiple data (MIMD) interconnected processors that could be programmed to target specific image-processing applications (“Processor targets medical, video applications,” Vision Systems Design, May 2008). After the company was acquired by Nethra Imaging (Santa Clara, CA, USA), the Ambric Am2045 processor is still supported and used in a number of products, most notably the Pyro Kompressor HD PCI Express board from the Pyro AV division of ADS Tech (Cerritos, CA, USA) for use in H.264 and HD MPEG-2 encoding applications.
Coherent Logix (Austin, TX, USA) has developed a memory-networked processing (MNP) architecture. Processing is performed by GPP/DSP cores, interconnected through a memory network. The hardware enables abstraction of a software programming model using high-level language constructs such as C and Simulink that, while they are similar to a GPP, incorporate the parallelization characteristics of an FPGA.
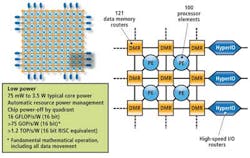
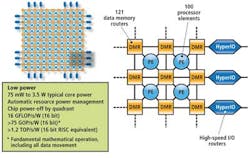
The latest hx3100 processor is made up of an array of 100 cores supporting 8-bit SIMD; 16-bit, extended precision integer; and 32-bit single precision floating point. The device is capable of 50 GMACs or 25 GFLOPs, with total device core power ranging from 75 mW to 3.5 W. Each processor comprises a 24-bit multiplier, 16-bit ALU, 40-bit accumulator, 32-bit floating point, and reciprocal and reciprocal square root processor.
These processors are each interconnected by an array of 121 8-kbyte data memory routers (DMRs) that are used to store data memory and facilitate autonomous data movement across the chip. For inter-device communication and I/O, the device also features a number of programmable I/O routers that support up to 104-Gbit/s data I/O through DDR2, LVDS, and CMOS interfaces (see Fig. 1).
To allow developers to evaluate the processor for image-processing applications, Coherent Logix has also introduced a video and imaging development system (VIDS). The VIDS platform consists of a system motherboard with a proprietary backplane that can be populated with hx3100 processor boards, GPPs, and I/O cards. For image capture and display, a dual-input Camera Link card (with independent Full and Base channels) and a DVI display card can be interfaced as daughter cards (see Fig. 2).

Many seasoned programmers of multiprocessor architectures will realize however, that though hardware support is important, the key to any successful implementation of such systems lies in how efficiently algorithms can be partitioned across their architectures. As Martin Hunt, video and imaging program manager at Coherent Logix, points out, developers must fully understand how complex algorithms can be effectively decomposed.
“By using dataflow programming methods, data dependencies between elementary transformations can be expressed and optimized, thus exploiting the intrinsic parallelism of the algorithm on the processor,” Hunt says. Such dataflow models are especially useful for image-processing algorithms, many of which by nature can be optimized for dataflow architectures such as the hx3100.
Hunt and his colleagues have already shown how these development models are especially useful in broadcast applications such as H.264 video encoding (see “A New Programming Methodology for Broadcast Video Encoding Using a Massively Parallel Processor,” SMPTE Motion Imaging Journal, pp. 45–54, April 2011, and “Parallel design patterns for a low-power, software-defined compressed video encoder,” Proc. SPIE Defense, Sensing & Security, conf. 8063, Orlando, FL, April 2011).
For image-processing applications, the company has also developed hyperspectral fusion and image stabilization applications and a number of library functions that include Bayer filter interpolation, convolution functions, frequency transforms, and MPEG and H.264 codecs. (see “Low-power, real-time digital video stabilization using the HyperX parallel processor,” Proc. SPIE Defense, Sensing & Security, conf. 8050, Orlando, FL, April 2011).
Coherent Logix has also alleviated the programmers’ need to understand the architecture of their devices, allowing ANSI C to be used to express various functions, while a variant of the message passing interface (MPI) (www.mpi-forum.org) is used to describe the communication between them.
By encapsulating these concepts in its HyperX Integrated System Development Environment (hxISDE), task allocation, memory allocation and inter-processor communication is abstracted from the programmer. This development software also allows the programmer to simulate, breakpoint, and analyze code and manually or automatically optimize on-chip processor and memory resources without requiring C code changes.
Vision Systems Articles Archives