How deep learning is enhancing machine vision
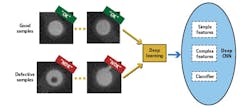
Developers increasingly apply deep learning and artificial neural networks to improve object detection and classification.
Johannes Hiltner
Digitalization has a firm grip on industrial production, with processes increasingly automated as part of the Industrial Internet of Things (IIoT). In the IIoT, which is also known as Industry 4.0, various machines and robots take on more everyday production tasks. In assembly for example, new, compact and mobile robots, such as collaborative robots (cobots), often work hand in hand with their human colleagues.
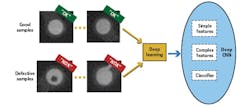
Deep learning technologies and convolutional neural networks (CNNs) can learn and distinguish between defects.
The IIoT's highly automated and universally networked production flows characterized by machine-to-machine interaction depend on machine vision to reliably identify a wide range of objects in the flow of goods within factories and the rest of the process chain. Machine vision increases the efficiency and safety of these workflows, and has become an indispensable tool for engineers seeking to automate and speed up production.
Today, innovative machine learning and deep learning processes can ensure even more robust recognition rates. Thanks to such advances in artificial intelligence, companies can benefit from a higher degree of automation, much greater productivity, and more reliable identification, allocation, and handling of a wider range of objects throughout the entire value chain.
As the "eye of production," machine vision software has become an essential element of the technology, processing unstructured data such as digital images and video generated by cameras to identify objects by their external optical features alone. Such software works very fast and achieves extremely high and reliable identification rates, and consequently, is used across industries for a wide range of tasks such as fault inspection, workpiece positioning and the automatic handling of objects in robotics.
Analyze and evaluate large data sets
In an effort to make the identification process even more robust and adaptable to the requirements of flexible and networked IIoT processes, machine vision software developers increasingly rely on methods from the field of artificial intelligence (AI). Deep learning is an area of machine learning that enables computers to be trained and learn through architectures such as convolutional neural networks (CNNs).
The special attribute of AI, machine-learning and deep-learning technologies is that they comprehensively analyze and evaluate large amounts of data (big data) in order to train many different classes and thereby more effectively distinguish between objects. Increasingly, this data is generated within the IIoT. This can be digital image information as well as data from sensors, scanners, and other process components.
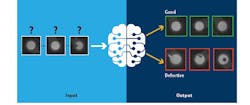
Methods such as deep-learning technologies and convolutional neural networks (CNNs) from the field of artificial intelligence (AI) are entering machine vision to help image-processing systems learn and distinguish between defects and make identification processes even more precise.
In order to use deep learning, CNNs must first be trained. This training process relates to certain external features that are typical of the object, such as color, shape, texture, and surface structure. The objects are divided into different classes based on these properties to allocate them more precisely later.
In conventional machine vision methods, a developer must laboriously define and verify the individual features manually. With deep learning, however, self-learning algorithms are used to automatically find and extract the unique patterns in order to differentiate between the particular classes.
Train objects through classification
How does the training process work exactly? The user first supplies image data that has already been provided with labels. Each label corresponds to a tag that indicates the identity of the particular object. The system analyzes this data, and-on this basis-creates or "trains" corresponding models of the objects to be identified.
Due to these self-learned object models, the deep learning network is now able to assign the newly-added image data to the appropriate classes, such that, their data content or objects are also classified. Thanks to this allocation to certain classes, the items can then continue to be identified automatically.
A sample image for direct comparison is therefore no longer necessary for each individual object. After all, deep learning processes are able to learn new things independently. By taking the features of all image data into account, conclusions can then be drawn about the properties of a certain class, which significantly improves the identification rates. This process is called "inference."
Therefore, deep learning algorithms are also very suitable for optical character recognition (OCR) applications, that is, for precisely identifying letter or number combinations. Due to the extensive training process, the typical features of the individual characters are precisely identified based on the defined classes. However, since there are many different fonts, some with deviating features such as serifs, problems may arise allocating them with certainty.
Modern machine-vision solutions enable companies to train neural networks themselves. Photo credit: MVTec Software GmbH
Advanced machine vision software can solve this problem. MERLIC and HALCON from MVTec (Munich, Germany; www.mvtec.com), for example, contain an OCR classifier based on deep learning algorithms, which can be accessed via many pre-trained fonts. As a result, a wide range of typefaces, such as dot-print, SEMI, industrial, and document-based ones, can be identified with certainty thanks to a single, universal, pre-trained classifier.
Avoid excessive training time
However, companies often shy away from using AI-based technologies such as deep learning, since, due to their complexity, they require developers to have extensive expertise. The training process generally requires many sample images to recognize objects.
Up to 100,000 comparison images may be needed for each class in order to achieve adequate recognition rates. Even if the necessary sample data is available, the training process takes up an enormous amount of time. Usually, the programming work for identifying different defect classes during fault inspection is extremely complex, too. The reason is that highly skilled employees with suitable training are required for this purpose.
Modern machine vision solutions, which already include a large number of deep learning functions, can help. The new version 17.12 of the standard software MVTec HALCON enables companies to train convolutional neural networks (CNN) themselves without a great deal of time and money. After all, the software is already equipped with two networks that are optimally pre-trained for industrial use - one is optimized for speed and the other for maximum recognition rates.
The training process, therefore, works with only a few sample images provided by the customer, and thus are tailored to the customers' exact applications, resulting in neural networks that can be precisely matched to the customer's specific requirements.
User companies can significantly reduce the amount of programming work needed by easily and systematically classifying new image data, saving time and money. Normally, they do not have to have any in-depth AI expertise. Companies can use their existing personnel without problems to train the network.
Detect defects efficiently
Recognizing defects is a time-consuming process because the appearance of defects, such as tiny scratches on an electronic part, can never be accurately described in advance. Therefore, it is very difficult to manually develop suitable algorithms that can detect any conceivable faults, based on sample images. An expert would have to manually view hundreds of thousands of images and program an algorithm that describes the error as precisely as possible based on his observations. This would simply take too long.
Deep learning technologies and CNNs, on the other hand, can independently learn certain characteristics of defects, and precisely define the corresponding problem classes. So, only 500 sample images are needed for each class, based on which the technology trains, verifies, and thereby precisely detects the different types of defects.
This process takes only a few hours. Not only does it minimize the amount of time required, but the recognition rates are also much higher than with manually programmed defect classes. The self-learning algorithms, therefore, help to significantly reduce identification errors, while the error quotas for manual programming can be inefficiently high.
Many industries benefit
Machine vision technologies based on deep learning and CNNs can be used profitably in many different branches of industry and applications. In the electronics industry, the inspection process can be automated and accelerated. With the help of self-learning methods, therefore, all conceivable product defects can be effectively detected - as described above.
Even the tiniest scratches or cracks in circuit boards, semiconductors, and other components are reliably identified, which allows the removal of corresponding parts to be automated.
The food and beverage industry benefits from deep learning technologies, too. For example, poor-quality fruits and vegetables can be detected more precisely before they are packaged or further processed.
The processes are also used in automotive engineering. This industry, in particular, is characterized by an especially high degree of automation. Here, for example, self-learning algorithms perfectly identify tiny paint defects that are not visible to the naked eye.
Another important area of application is pharmaceuticals. Pills often look very similar on the outside, but contain entirely different active substances. Through deep learning and CNNs, the drugs can be very reliably identified, inspected, and distinguished from each other so they are always placed in the correct blister packs.
Conclusion
Technologies based on artificial intelligence, such as deep learning and CNNs, are an important part of modern machine vision solutions today. Deep learning enables companies to train neural networks themselves without any in-depth expert knowledge and minimal effort, especially when programming defect classes during error inspections. The result is that companies can save money and benefit from much more robust recognition rates as well as better classification results.
Johannes Hiltner is a product manager at MVTec Software GmbH (Munich,
Germany; www.mvtec.com) and responsible for the HALCON software, the company's flagship product.