MIT researchers develop algorithm for better robotic navigation and scene understanding
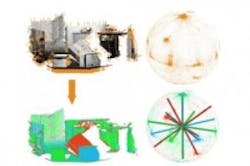
MIT researchers have developed an algorithm based on sets of orthogonal and parallel planes called Manhattan frames that can be used to determine the orientation of objects and aid in robotic navigation and scene understanding.
MIT compares the computer vision method of identifying major orientations in 3D scenes to the way that a person may use a skyscraper as a reference point as they weave in and out of traffic. As a person loses sight of a landmark and it reappears, you must be able to identify the landmark in order to use it for navigation. This algorithm, developed by Julian Straub, a graduate student in electrical engineering and computer science at MIT and lead author on an academic paper on the project, would make these “re-identification” process much easier for computers.
First, 3D data is captured by a Microsoft Kinect or laser rangefinder. Using established parameters, the algorithm then estimates the orientations of a large number of individual points in the scene, and those orientations are then represented as points on the surface of a sphere, with each point defining a unique angle relative to the center of the sphere. Initial orientation estimates can be rough, so the points on the sphere form loose clusters that can be difficult to distinguish. As a result, the researchers employ statistical information about the uncertainty of the initial orientation estimates and the algorithm then tries to fit Manhattan frames to the points on the sphere.
This process is described as being similar to regression analysis, which involves finding lines that best approximate scatters of points, but it is more complicated because of the geometry of the sphere. While it would be possible to approximate the point data accurately by using hundreds of different Manhattan frames, it would yield a model too complex for use. Consequently, the algorithm weighs the accuracy of approximation against number of frames by starting with a fixed number of frames—between 3 and 10, depending on the complexity of the scene—and tries to pare that number down.
Plane segmentation—the process of deciding which elements of the scene lie in which planes and at which depth—allows a computer to build 3D models of objects in a scene, which could in turn match to stored 3D models of known objects. With this algorithm, once the set of Manhattan frames is determined, plane segmentation becomes easier.
This MIT-developed algorithm is primarily intended to aid robots navigating unfamiliar buildings. As a robot moved, it would “observe the sphere rotating in the opposite direction” and could gauge its orientation in relation to the axes. Whenever the robot wanted to reorient itself, it would know which of its landmark’s faces should be toward it, making them easier to identify.
View the MIT press release.
Also check out:
Developers look to open sources for machine vision and image processing algorithms
Algorithms provide more accurate citrus crop yield estimate
Vision-based inspection system enhances undercarriage security on trains
Share your vision-related news by contacting James Carroll, Senior Web Editor, Vision Systems Design
To receive news like this in your inbox, click here.
Join our LinkedIn group | Like us on Facebook | Follow us on Twitter | Check us out on Google +
About the Author

James Carroll
Former VSD Editor James Carroll joined the team 2013. Carroll covered machine vision and imaging from numerous angles, including application stories, industry news, market updates, and new products. In addition to writing and editing articles, Carroll managed the Innovators Awards program and webcasts.