Edge device uses inexpensive, off-the-shelf components for deep learning inference

Inference involves the use of a neural network trained through deep learning that makes predictions on new data. Inference is a more effective way to answer complex and subjective questions than traditional rules-based image analysis. By optimizing networks to run on low-power hardware, inference can be run on the edge, eliminating dependency on a central server for image analysis, which can lead to lower latency, higher reliability, and improved security. Here, the specification and building of an edge-based deep learning inference system suitable for real-life deployment that will cost users less than $1,000 isdescribed.
The goal of the project, according to Mike Fussell, Product Marketing Manager, FLIR Integrated Imaging Systems (Richmond, BC, Canada; www.flir.com/mv) was to build a reliable system to deploy for real-life applications such as industrial inspection. First, an AAEON (New Taipei City, Taiwan; www.aaeon.com) UP Squared-Celeron-4GB-32GB single-board computer was chosen, as it has the required memory and CPU power. This SBC has an X64 CPU running the same software as desktop PCs, simplifying development compared to ARM-based SBCs.


Well-labeled (left) and poorly-labeled (right) training data for “flowers.” While both sets of images contain flowers, the images in set B are less relevant to the “flower” label than set A.
Deep learning inference-enabling code uses branching logic, and dedicated hardware greatly accelerates the execution of the code. The Intel (Santa Clara, CA, USA; www.intel.com) Movidius Myriad 2 Vision Processing Unit (VPU) is a compact, low-power board that can be integrated into such edge-computing devices as the Intel Neural Compute Stick, or the AAEON AI Core micro PCIe add-on board for AAEON UP2 SBCs. For the camera, a Blackfly S camera from FLIR, the FLIR BFS-U3-16S2C-C, was chosen. This USB3 Vision camera features the 1.6 MPixel Sony IMX273 color CMOS sensor. Paired with the camera was an A4Z2812CS-MPIR, 1/2.7”, CS-Mount Lens from Computar (Cary, NC, USA; www.computar.com).
Related: Smart vision system ensures 100% cylinder bore inspection
In this demonstration, a number of free and open-source software options were used. This includes the Ubuntu 16.04 operating system. TensorFlow—a popular open-source software library used for deep learning—provides a Python API, enabling users to build and train deep neural networks. Installation instructions are available from TensorFlow here: http://bit.ly/VSD-TSF. As the UP Squared board does not have a GPU, the variant without NVIDIA GPU support should be installed.
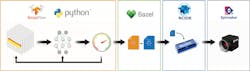
Deep learning inference workflow and the associated tools for each step are shown here.
Next, Bazel—a free tool used to build the required TensorFlow tools for graph conversion—is utilized. Installation instructions are available from the developer: http://bit.ly/VSD-BZL. Converting a neural network to Movidius format and uploading it to the Myriad 2 VPU requires the Intel Neural Compute Stick Software Development Kit (NCSDK). Installation instructions for Linux are available from Intel here: http://bit.ly/VSD-NCSDK. FLIR’s Spinnaker software development kit—a GenICam API library—is used to control the camera.
Related: Deep learning promises automotive inspection improvements
For this example, Google’s “TensorFlow for Poets” tutorial was used as a starting point. This can be located here: http://bit.ly/VSD-TSF4P. Clone the git repository for this tutorial to download the scripts used in this example:
git clone https://github.com/googlecodelabs/tensorflow-for-poets-2
cd tensorflow-for-poets-2
In this example, a neural network used to classify several different types of common flowers is trained. To do so, MobileNet—a type of deep neural network that can be deployed on mobile devices—was used, as it is ideal for deployment to the Myriad 2 VPU.
Having a good set of labeled training data is the most important requirement for training a neural network. Requirements for these images include image quality, accurate and noise-free label data, and the same aspect ratio and dimensions for all images.


Image data normalised using the Y = (x–x.mean()) / x.std() method can yield significant improvements in training speed and accuracy.
The quality and quantity of the images in the dataset used in this example are such that it can be used without further processing. This dataset can be downloaded from TensorFlow:
curl http://download.tensorflow.org/example_images/flower_photos.tgz
| tar xz -C tf_files
Training of the neural network on the dataset was done using transfer learning, which takes a pre-trained image classifier and retrains it to recognize new objects using a base task as a starting point, which is faster than training a network from scratch. For this example, input images of 224 x 224 and a model that is 0.5 times the size of the largest possible MobileNet model were used:
IMAGE_SIZE=224
ARCHITECTURE=”mobilenet_0.50_${IMAGE_SIZE}”
To monitor the progress of training, launch the TensorBoard tool:
tensorboard —logdir tf_files/training_summaries &
From here, the MobileNet can be retrained:
python -m scripts.retrain
—bottleneck_dir=tf_files/bottlenecks
—how_many_training_steps=500
—model_dir=tf_files/models/
—summaries_dir=tf_files/training_summaries/”${ARCHITECTURE}”
—output_graph=tf_files/retrained_graph.pb
—output_labels=tf_files/retrained_labels.txt
—architecture=”${ARCHITECTURE}”
—image_dir=tf_files/flower_photos
This process takes time and can be monitored using the TensorBoard tool. Once the model has been retrained, it is saved as tf_files/retrained_graph.pb, and this can be tested on a sample image from the training dataset:
python -m scripts.label_image
—graph=tf_files/retrained_graph.pb
—image=tf_files/flower_photos/daisy/21652746_cc379e0eea_m.jpg
To run the model on new images that are not part of the original dataset, point the —image flag to the location of a new image. If this new image is a different size than those in the dataset, it is necessary to add the —input_size=${IMAGE_SIZE} flag to the previous shell command or resize it manually.
Before the retrained model can be deployed to the VPU, it must be optimized for Intel’s NCSDK, which is done using TensorFlow and Bazel:
bazel build tensorflow/tools/graph_transforms:transform_graph
/home/username/Public/Projects/tensorflow/tensorflow/bazel-bin/tensorflow/tools/graph_transforms/transform_graph
—in_graph=/home/username/Public/Projects/tf_poets/tf_files/retrained_graph.pb
—out_graph=/home/username/Public/Projects/tf_poets/tf_files/optimized_graph.pb
—inputs=’input’
—outputs=’final_result’
—transforms=’
strip_unused_nodes(type=float, shape=”1,224,224,3”)
remove_nodes(op=Identity, op=CheckNumerics, op=PlaceholderWithDefault)
fold_batch_norms
fold_old_batch_norms’
Bazel enables the benchmarking of the performance of the model. This step is not required, but it can be useful to help optimize more complex models:
bazel build tensorflow/tools/benchmark:benchmark_model
bazel run tensorflow/tools/benchmark:benchmark_model
—graph=/home/username/Public/Projects/tf_poets/tf_files/optimized_graph.pb
—show_flops
—input_layer=input
—input_layer_type=float
—input_layer_shape=1,224,224,3
—output_layer=final_result
The resulting graph file can now be converted into a Movidius-supported format and uploaded to the VPU:
mvNCCompile -s 12 tf_files/optimized_graph.pb -in=input -on=final_result
Lastly, now that the graph file has been uploaded to the VPU, inference can be run on the images captured by the camera. This script (http://bit.ly/VSD-FLIR) calls the Spinnaker API to acquire images which are resized to match the network input and normalized. The images are then passed to the VPU, where they are classified based on the neural network that was just trained:
python3 lic2.py —graph graph_filename —labels labels_camera_3classes.txt